Initial Remark: Reload this page if formulas don’t display well!
As promised, here is the second part on how to obtain confidence intervals for fitted values obtained from nonlinear regression via nls or nlsLM (package ‘minpack.lm’).
I covered a Monte Carlo approach in https://rmazing.wordpress.com/2013/08/14/predictnls-part-1-monte-carlo-simulation-confidence-intervals-for-nls-models/, but here we will take a different approach: First- and second-order Taylor approximation around 
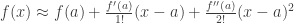
Using Taylor approximation for calculating confidence intervals is a matter of propagating the uncertainties of the parameter estimates obtained from vcov(model) to the fitted value. When using first-order Taylor approximation, this is also known as the “Delta method”. Those familiar with error propagation will know the formula
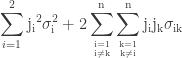
Heavily underused is the matrix notation of the famous formula above, for which a good derivation can be found at http://www.nada.kth.se/~kai-a/papers/arrasTR-9801-R3.pdf:

where 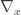
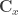
For highly nonlinear functions we need (at least) a second-order polynomial around 

Interestingly, there are also matrix-like notations for the second-order mean and variance in the literature (see http://dml.cz/dmlcz/141418 or http://iopscience.iop.org/0026-1394/44/3/012/pdf/0026-1394_44_3_012.pdf):
Second-order mean: ![\rm{E}[y] = f(\bar{x}_i) + \frac{1}{2}\rm{tr}(\mathbf{H}_{xx}\mathbf{C}_x)](https://s0.wp.com/latex.php?latex=%5Crm%7BE%7D%5By%5D+%3D+f%28%5Cbar%7Bx%7D_i%29+%2B+%5Cfrac%7B1%7D%7B2%7D%5Crm%7Btr%7D%28%5Cmathbf%7BH%7D_%7Bxx%7D%5Cmathbf%7BC%7D_x%29&bg=ffffff&fg=333333&s=0&c=20201002)
Second-order variance: 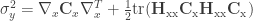
where 
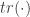
Enough theory, for wrapping this all up we need three utility functions:
1) numGrad for calculating numerical first-order partial derivatives.
numGrad <- function(expr, envir = .GlobalEnv)
{
f0 <- eval(expr, envir)
vars <- all.vars(expr)
p <- length(vars)
x <- sapply(vars, function(a) get(a, envir))
eps <- 1e-04
d <- 0.1
r <- 4
v <- 2
zero.tol <- sqrt(.Machine$double.eps/7e-07)
h0 <- abs(d * x) + eps * (abs(x) < zero.tol)
D <- matrix(0, length(f0), p)
Daprox <- matrix(0, length(f0), r)
for (i in 1:p) {
h <- h0
for (k in 1:r) {
x1 <- x2 <- x
x1 <- x1 + (i == (1:p)) * h
f1 <- eval(expr, as.list(x1))
x2 <- x2 - (i == (1:p)) * h
f2 <- eval(expr, envir = as.list(x2))
Daprox[, k] <- (f1 - f2)/(2 * h[i])
h <- h/v
}
for (m in 1:(r - 1)) for (k in 1:(r - m)) {
Daprox[, k] <- (Daprox[, k + 1] * (4^m) - Daprox[, k])/(4^m - 1)
}
D[, i] <- Daprox[, 1]
}
return(D)
}
2) numHess for calculating numerical second-order partial derivatives.
numHess <- function(expr, envir = .GlobalEnv)
{
f0 <- eval(expr, envir)
vars <- all.vars(expr)
p <- length(vars)
x <- sapply(vars, function(a) get(a, envir))
eps <- 1e-04
d <- 0.1
r <- 4
v <- 2
zero.tol <- sqrt(.Machine$double.eps/7e-07)
h0 <- abs(d * x) + eps * (abs(x) < zero.tol)
Daprox <- matrix(0, length(f0), r)
Hdiag <- matrix(0, length(f0), p)
Haprox <- matrix(0, length(f0), r)
H <- matrix(NA, p, p)
for (i in 1:p) {
h <- h0
for (k in 1:r) {
x1 <- x2 <- x
x1 <- x1 + (i == (1:p)) * h
f1 <- eval(expr, as.list(x1))
x2 <- x2 - (i == (1:p)) * h
f2 <- eval(expr, envir = as.list(x2))
Haprox[, k] <- (f1 - 2 * f0 + f2)/h[i]^2
h <- h/v
}
for (m in 1:(r - 1)) for (k in 1:(r - m)) {
Haprox[, k] <- (Haprox[, k + 1] * (4^m) - Haprox[, k])/(4^m - 1)
}
Hdiag[, i] <- Haprox[, 1]
}
for (i in 1:p) {
for (j in 1:i) {
if (i == j) {
H[i, j] <- Hdiag[, i]
}
else {
h <- h0
for (k in 1:r) {
x1 <- x2 <- x
x1 <- x1 + (i == (1:p)) * h + (j == (1:p)) *
h
f1 <- eval(expr, as.list(x1))
x2 <- x2 - (i == (1:p)) * h - (j == (1:p)) *
h
f2 <- eval(expr, envir = as.list(x2))
Daprox[, k] <- (f1 - 2 * f0 + f2 - Hdiag[, i] * h[i]^2 - Hdiag[, j] * h[j]^2)/(2 * h[i] * h[j])
h <- h/v
}
for (m in 1:(r - 1)) for (k in 1:(r - m)) {
Daprox[, k] <- (Daprox[, k + 1] * (4^m) - Daprox[, k])/(4^m - 1)
}
H[i, j] <- H[j, i] <- Daprox[, 1]
}
}
}
return(H)
}
And a small function for the matrix trace:
tr <- function(mat) sum(diag(mat), na.rm = TRUE)
1) and 2) are modified versions of the genD function in the “numDeriv” package that can handle expressions.
Now we need the predictNLS function that wraps it all up:
predictNLS <- function(
object,
newdata,
interval = c("none", "confidence", "prediction"),
level = 0.95,
...
)
{
require(MASS, quietly = TRUE)
interval <- match.arg(interval)
## get right-hand side of formula
RHS <- as.list(object$call$formula)[[3]]
EXPR <- as.expression(RHS)
## all variables in model
VARS <- all.vars(EXPR)
## coefficients
COEF <- coef(object)
## extract predictor variable
predNAME <- setdiff(VARS, names(COEF))
## take fitted values, if 'newdata' is missing
if (missing(newdata)) {
newdata <- eval(object$data)[predNAME]
colnames(newdata) <- predNAME
}
## check that 'newdata' has same name as predVAR
if (names(newdata)[1] != predNAME) stop("newdata should have name '", predNAME, "'!")
## get parameter coefficients
COEF <- coef(object)
## get variance-covariance matrix
VCOV <- vcov(object)
## augment variance-covariance matrix for 'mvrnorm'
## by adding a column/row for 'error in x'
NCOL <- ncol(VCOV)
ADD1 <- c(rep(0, NCOL))
ADD1 <- matrix(ADD1, ncol = 1)
colnames(ADD1) <- predNAME
VCOV <- cbind(VCOV, ADD1)
ADD2 <- c(rep(0, NCOL + 1))
ADD2 <- matrix(ADD2, nrow = 1)
rownames(ADD2) <- predNAME
VCOV <- rbind(VCOV, ADD2)
NR <- nrow(newdata)
respVEC <- numeric(NR)
seVEC <- numeric(NR)
varPLACE <- ncol(VCOV)
outMAT <- NULL
## define counter function
counter <- function (i)
{
if (i%%10 == 0)
cat(i)
else cat(".")
if (i%%50 == 0)
cat("\n")
flush.console()
}
## calculate residual variance
r <- residuals(object)
w <- weights(object)
rss <- sum(if (is.null(w)) r^2 else r^2 * w)
df <- df.residual(object)
res.var <- rss/df
## iterate over all entries in 'newdata' as in usual 'predict.' functions
for (i in 1:NR) {
counter(i)
## get predictor values and optional errors
predVAL <- newdata[i, 1]
if (ncol(newdata) == 2) predERROR <- newdata[i, 2] else predERROR <- 0
names(predVAL) <- predNAME
names(predERROR) <- predNAME
## create mean vector
meanVAL <- c(COEF, predVAL)
## create augmented variance-covariance matrix
## by putting error^2 in lower-right position of VCOV
newVCOV <- VCOV
newVCOV[varPLACE, varPLACE] <- predERROR^2
SIGMA <- newVCOV
## first-order mean: eval(EXPR), first-order variance: G.S.t(G)
MEAN1 <- try(eval(EXPR, envir = as.list(meanVAL)), silent = TRUE)
if (inherits(MEAN1, "try-error")) stop("There was an error in evaluating the first-order mean!")
GRAD <- try(numGrad(EXPR, as.list(meanVAL)), silent = TRUE)
if (inherits(GRAD, "try-error")) stop("There was an error in creating the numeric gradient!")
VAR1 <- GRAD %*% SIGMA %*% matrix(GRAD)
## second-order mean: firstMEAN + 0.5 * tr(H.S),
## second-order variance: firstVAR + 0.5 * tr(H.S.H.S)
HESS <- try(numHess(EXPR, as.list(meanVAL)), silent = TRUE)
if (inherits(HESS, "try-error")) stop("There was an error in creating the numeric Hessian!")
valMEAN2 <- 0.5 * tr(HESS %*% SIGMA)
valVAR2 <- 0.5 * tr(HESS %*% SIGMA %*% HESS %*% SIGMA)
MEAN2 <- MEAN1 + valMEAN2
VAR2 <- VAR1 + valVAR2
## confidence or prediction interval
if (interval != "none") {
tfrac <- abs(qt((1 - level)/2, df))
INTERVAL <- tfrac * switch(interval, confidence = sqrt(VAR2),
prediction = sqrt(VAR2 + res.var))
LOWER <- MEAN2 - INTERVAL
UPPER <- MEAN2 + INTERVAL
names(LOWER) <- paste((1 - level)/2 * 100, "%", sep = "")
names(UPPER) <- paste((1 - (1- level)/2) * 100, "%", sep = "")
} else {
LOWER <- NULL
UPPER <- NULL
}
RES <- c(mu.1 = MEAN1, mu.2 = MEAN2, sd.1 = sqrt(VAR1), sd.2 = sqrt(VAR2), LOWER, UPPER)
outMAT <- rbind(outMAT, RES)
}
cat("\n")
rownames(outMAT) <- NULL
return(outMAT)
}
With all functions at hand, we can now got through the same example as used in the Monte Carlo post:
DNase1 <- subset(DNase, Run == 1)
fm1DNase1 <- nls(density ~ SSlogis(log(conc), Asym, xmid, scal), DNase1)
> predictNLS(fm1DNase1, newdata = data.frame(conc = 5), interval = "confidence")
.
mu.1 mu.2 sd.1 sd.2 2.5% 97.5%
[1,] 1.243631 1.243288 0.03620415 0.03620833 1.165064 1.321511
The errors/confidence intervals are larger than with the MC approch (who knows why?) but it is very interesting to see how close the second-order corrected mean (1.243288) comes to the mean of the simulated values from the Monte Carlo approach (1.243293)!
The two approach (MC/Taylor) will be found in the predictNLS function that will be part of the “propagate” package in a few days at CRAN…
Cheers,
Andrej

Hi Anrej,
This is really cool and I have been looking for something that can calculate a single confidence interval for NLS models for quite some time. I have tried to use your function on some of the models that I have and it seems to work perfectly for models with a single predictor variable. However, when I use multiple predictor variables it is not working. Any ideas how to work around that?
With kind regards,
Robbie
I think ‘nls’ is only applicable for one-dimensional problems… When you say “multiple predictors”, do you mean that you are i.e. fitting surfaces and use x/y as predictor variables?
Greets,
Andrej
Hi Andrej,
I have for example a model in which I have a variable that is modelled against 3 predictor variables:
model <- nls(rate ~ ((a * prey)* size^b)/((1 + c * prey) * (1 + d * (pred-1)))….)
In which a, b, c and d are the parameter estimates and prey, pred and size are the predictor variables. This seem to work perfectly and the outputs seem to make sense. Only those dreadful confidence intervals.
I am not a statistician so you could be right that NLS can only be used for models with one predictor variable. Nevertheless, I have seen it being used this way in one of the Use R! books: Nonlinear Regression with R by Ritz & Streibig (2008). They give an example somewhere on page 45.
I have been playing a bit with the function you give here to get it working for my model, but still without success (for now).
Thanks Robbie
@Robbie:
I will submit my new ‘propagate’ package to CRAN in the next days. This will have the predictNLS function included that does MC simulation and Taylor approximation under one hood. I will try to incorporate the handling of multiple predictor values, so stay tuned at these comments!
Cheers,
Andrej
Hi Andrej,
Looking forward to that, already have some research papers waiting here to implement this.
Thanks
[…] error to the fitted values of a nonlinear model of type nls or nlsLM. Please refer to my post here: https://rmazing.wordpress.com/2013/08/26/predictnls-part-2-taylor-approximation-confidence-intervals-…. * makeGrad, makeHess, numGrad, numHess are functions to create symbolical or numerical gradient […]
Andrej,
I am very pleased to see your predictNLS function made available in an R package. Thank you. Now, how about prediction intervals, as well as confidence and prediction bands (regions)? That would be super.
BTW, I notice the posts questioning the use of “nls” for models with multiple predictor variables. I have been regularly using “nls” to fit models with up to 5 predictors with great success. I hope your predictNLS performs appropriately in that context.
Best regards,
Leland
Hi Leland,
the last two examples in the ‘Examples’ section of ?predictNLS show you how to draw confidence/prediction intervals (by setting ‘interval’ in the function) and how to use multiple predictor values with error.
Drop me a note if it works in your hands!
Cheers,
Andrej
Andrej,
Going through the code, it seems GRAD %*% SIGMA %*% matrix(GRAD) is problematic because the row names and column names are not corresponding to the gradients in GRAD. Using the PROP2 example in the help file, the 3rd entry of GRAD corresponds to conc while conc corresponds to the 4th row and 4th column in SIGMA. Not sure if that’s fixed or not in the released package.
Thanks,
Da
Thanks, will look into it right away!
Checked it and using the PROP2 example this gives:
1. covariance matrix
Asym xmid scal conc
Asym 0.006108013 0.006273972 0.002271984 0
xmid 0.006273972 0.006618323 0.002379381 0
scal 0.002271984 0.002379381 0.001041403 0
conc 0.000000000 0.000000000 0.000000000 0
2. the gradient vector:
$Asym
1/(1 + exp((xmid – log(conc))/scal))
$xmid
-(Asym * (exp((xmid – log(conc))/scal) * (1/scal))/(1 + exp((xmid –
log(conc))/scal))^2)
$scal
Asym * (exp((xmid – log(conc))/scal) * ((xmid – log(conc))/scal^2))/(1 + exp((xmid – log(conc))/scal))^2
$conc
Asym * (exp((xmid – log(conc))/scal) * (1/conc/scal))/(1 + exp((xmid – log(conc))/scal))^2
So the order is correct and conc is the 4th position, which I’m happy about… Why do you have the 3rd position?
Cheers,
Andrej
Thank you for the reply. I think the error is just in the script above, not in the released package. For example, numGrad returns D as 0.1940266 -0.3521419 0.3521419 0.5014695
for conc = 1, where the 2nd the 3rd entries have opposite signs, which is exactly the case for the gradients of xmid and conc when conc = 1.
Thanks,
Da