Calculation of the propagated uncertainty 
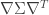


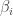
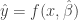




Confidence and prediction intervals for NLS models are calculated using 


Now, how can we employ the matrix notation of error propagation for creating Taylor expansion- and Monte Carlo-based prediction intervals?
The inclusion of 




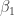
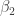
![\left[\frac{\partial f}{\partial \beta_1}\; \frac{\partial f}{\partial \beta_2}\; 1\right] \left[ \begin{array}{ccc} \;\sigma_1^2\;\;\; \sigma_1\sigma_2\;\; 0 \\ \sigma_2\sigma_1\;\; \sigma_2^2\;\;\;\; 0 \\ \;\;\;0\;\;\;\;\;\; 0\;\;\;\;\; \sigma_r^2 \end{array} \right] \left[ \begin{array}{c} \frac{\partial f}{\partial \beta_1} \\ \frac{\partial f}{\partial \beta_2} \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+%5Cbeta_1%7D%5C%3B+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+%5Cbeta_2%7D%5C%3B+1%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+%5C%3B%5Csigma_1%5E2%5C%3B%5C%3B%5C%3B+%5Csigma_1%5Csigma_2%5C%3B%5C%3B+0+%5C%5C+%5Csigma_2%5Csigma_1%5C%3B%5C%3B+%5Csigma_2%5E2%5C%3B%5C%3B%5C%3B%5C%3B+0+%5C%5C+%5C%3B%5C%3B%5C%3B0%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B+0%5C%3B%5C%3B%5C%3B%5C%3B%5C%3B+%5Csigma_r%5E2+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+%5Cbeta_1%7D+%5C%5C+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+%5Cbeta_2%7D+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)


The advantage of the augmented covariance matrix is that it can be exploited for creating Monte Carlo-based prediction intervals. This is new from propagate version 1.0-6 and is based on the paradigm that we add another dimension by employing the augmented covariance matrix of (8) in the multivariate t-distribution random number generator (in our case rtmvt), with 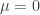

![[1 - \frac{\alpha}{2}, \frac{\alpha}{2}]](https://s0.wp.com/latex.php?latex=%5B1+-+%5Cfrac%7B%5Calpha%7D%7B2%7D%2C+%5Cfrac%7B%5Calpha%7D%7B2%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Application of second-order Taylor expansion or the MC-based approach demonstrates nicely that for the majority of nonlinear models, the confidence/prediction intervals around
library(propagate)
DNase1 <- subset(DNase, Run == 1)
fm3DNase1 <- nls(density ~ Asym/(1 + exp((xmid - log(conc))/scal)),
data = DNase1, start = list(Asym = 3, xmid = 0, scal = 1))
## first-order prediction interval
set.seed(123)
PROP1 <- predictNLS(fm3DNase1, newdata = data.frame(conc = 2), nsim = 1000000,
second.order = FALSE, interval = "prediction")
t(PROP1$summary)

## second-order prediction interval and MC
set.seed(123)
PROP2 <- predictNLS(fm3DNase1, newdata = data.frame(conc = 2), nsim = 1000000,
second.order = TRUE, interval = "prediction")
t(PROP2$summary)

What we see here is that
i) the first-order prediction interval [0.70308712; 0.79300731] is symmetric and slightly down-biased compared to the second-order one [0.70317629; 0.79309874],
and
ii) the second-order prediction interval tallies nicely up to the 4th decimal with the new MC-based interval (0.70318286 and 0.70317629; 0.79311987 and 0.79309874).
I believe this clearly demonstrates the usefulness of the MC-based approach for NLS prediction interval estimation…
