I have been working with R for some time now, but once in a while, basic functions catch my eye that I was not aware of…
For some project I wanted to transform a correlation matrix into a covariance matrix. Now, since cor2cov does not exist, I thought about “reversing” the cov2cor function (stats:::cov2cor).
Inside the code of this function, a specific line jumped into my retina:
r[] <- Is * V * rep(Is, each = p)
What’s this [ ]?
Well, it stands for every element 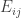

mat <- matrix(NA, nrow = 5, ncol = 5)
> mat
[,1] [,2] [,3] [,4] [,5]
[1,] NA NA NA NA NA
[2,] NA NA NA NA NA
[3,] NA NA NA NA NA
[4,] NA NA NA NA NA
[5,] NA NA NA NA NA
With the empty bracket, we can now substitute ALL values by a new value:
mat[] <- 1
> mat
[,1] [,2] [,3] [,4] [,5]
[1,] 1 1 1 1 1
[2,] 1 1 1 1 1
[3,] 1 1 1 1 1
[4,] 1 1 1 1 1
[5,] 1 1 1 1 1
Interestingly, this also works with lists:
L <- list(a = 1, b = 2, c = 3)>L
$a
[1] 1$b
[1] 2$c
[1] 3L[] <- 5> L $a [1] 5 $b [1] 5 $c [1] 5 Cheers, Andrej

awesome thanks! one good turn deserves another.
In case you didn’t resolve cor2cov, here’s an eg:
#__________________
# this code shows how to build correlated series, which in this case have lognormal error
# the example represents four time series (so the matrices are 4×4)
require(MASS)
sd<-log(1.2)
cov.mat<-matrix(c(sd^2,0,0,0,
0,sd^2,0,0,
0,0,sd^2,0,
0,0,0,sd^2),
ncol=4,byrow=T)
# correlation of 50% between series
cor.mat<- matrix(c(1,0.5,0.5,0.5,
0.5,1,0.5,0.5,
0.5,0.5,1,0.5,
0.5,0.5,0.5,1),ncol=4)
# next two lines are cor2cov():
d <- sqrt(diag(cov.mat))
cov.mat2 <- outer(d, d)*cor.mat
cov.mat2
#demonstrating the math is correct:
cov2cor(cov.mat2)
junk<-mvrnorm(100000,mu=rep(log(1e4),4),cov.mat2)
junk2<-exp(junk)
# demonstrating the sampled results have desired correlation:
cor(junk2)
acf(junk2)
Thanks for the code, works like charm!
Great tip, will come in handy (a.s.)
Maybe drop a line to Norman S. Matloff, he can add it to the next addition of “the art of R programming”.
Hmm, can’t imagine it isn’t in there yet…
I will have a look. Thanks for the suggestion!
To make this post complete, you might want to discuss what happens to “r” when you type
> r r[] <- something
Hmm, dunno what you mean… Is your code line correct?
Cheers,
Andrej
Sorry — something fouled up there. I wanted to compare
> r[ ] r <- something
in both the case where "r" previously existed and where it did not.
OK, let me try that again. WordPress is destroying lines of text near the character “>” so pretend the prompt is “%”
% r <- something
vs
% r[] <- something
Ok!
r[] <- 5 will fill each element of an existing object with 5 while r <- something, if r already exists, will results in a new object r with a single value 5.
What would be really nice as a syntax:
r[] <- 5 * r[]
doing an element-wise function as a loop instead of lapply.
Should be possible, since lists are stored internally as C objects, not?
Cheers.
Isn’t this just the same thing as r[,]<-5, which (to my mind) more transparently sets all the elements in all the rows and all the columns to 5?
Yes, you’re right. The version r[] <- 5 works on matrices, data.frames and lists though…
Greets,
Andrej
True – except that if you screw up and type r[,,,]<- 42 but r happens to be of rank !=4 , it'll throw an error. using r[ ] avoids this risk.
Reblogged this on Stats in the Wild and commented:
I didn’t know this either!